
Ten months straight and no days off for good behavior
Last week, The Pandora Device completed its ten-month-long render, converting the 480i tape sources into 4K 60fps output. Just in time for summer too, where I would otherwise lament having an active space-heater in my office during hot days. The process involved using two AI algorithms/models, yielding slightly different results with both advantages and drawbacks, enabling us to choose which model suits each scene or shot best.
The final data footprint of the output came just shy of 16 Terabytes! Unfortunately, we had to use a slightly (barely) lossy codec; otherwise, the data footprint would have been over 34 Terabytes of data.
Here are some screenshots of the upscaled outputs…




For now, we believe we are done with the AI/machine learning upscale process. However, if there are any drastic improvements or new algorithms/models in the near future, we may consider a 3rd pass. Still, we also understand that window is closing as we draw close to the next stage of development. Ideally, even with a 3rd pass, we hope it may be a simple source asset swap for our editing suite once it is finished processing (if we explore that route).
Early composite tests yield promising results
Eager to test the new renders, I immediately began experimenting with live composites, utilizing some of our already reconstructed (though still in progress) native 4K backgrounds. We are fortunate that the footage was shot so well, with great care and attention to the proper lighting of both subjects and the bluescreen studio backdrops. This made the compositing process during the test relatively smooth.

From the above image, we can see how the upscaled footage provides some excellent and sharp results for the subjects and enables a clean key of the actors into their environments.
But there are still challenges ahead
While early tests showcase some amazing quality, a few caveats require further exploration—for example, high motion.
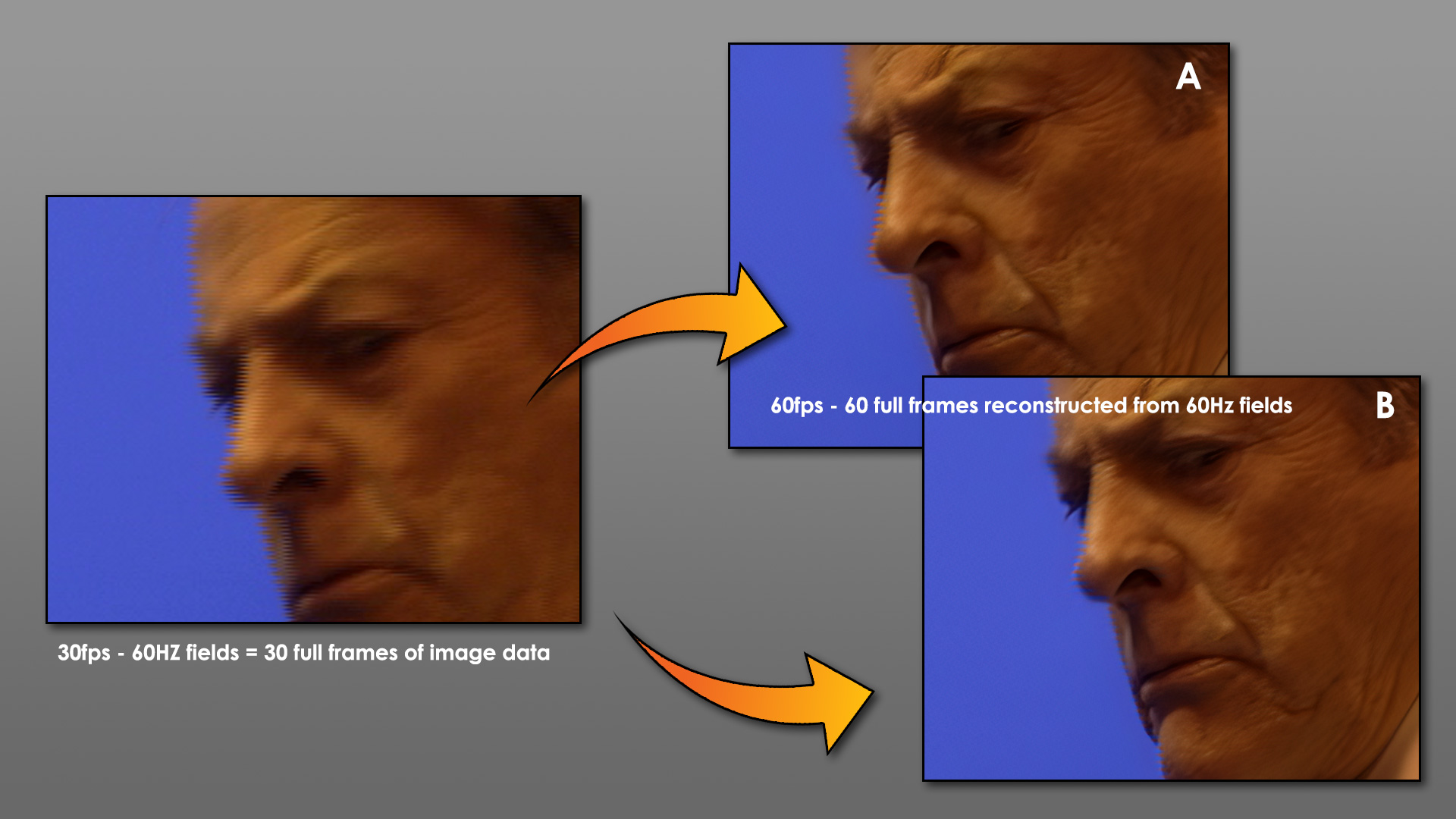
Interlaced formats were notorious for being terrible at handling high-motion because of an effect called “combing.” This is because interlaced sources worked with “fields” rather than full frames. Unfortunately, each field comprised only 50% of image data, rendering every second line of the image. The A-field would render all the odd lines, and the B-field would render all the even lines. This meant if an object was moving across the screen fast enough to be in a significantly different position between the two fields, it would create a “combing” effect on the image.

The interlaced method was used heavily (especially in tape media) to save on bandwidth for broadcast applications. Still, it was naturally inferior to recording in full frames (otherwise known as “progressive” frames”). Thankfully, deinterlacing has come a long way since those days, and most modern tools (especially those which handle AI/machine learning) have figured out ways to compensate for this.
There are two ways you can deinterlace a source signal:
- Combine the two fields (presented at 60Hz) into 30 full frames, where the A and B field)is combined. This may introduce blurring.
- Individually reconstruct the single fields, using AI to fill the alternate lines in the field using its algorithm, resulting in 60 full frames.
Regardless of which of the above methods is employed, both result in combing. However, its effects are significantly less prevalent when the motion is happening in front of an already populated image…

If we look at the image above, notice how despite Tex’s hand and the glass moving across the scene, causing combing on the source image, the deinterlaced output (using the reconstruction method) results in an almost immaculate image with virtually no combing. This is because behind the motion, there’s additional image data from which to extrapolate the reconstruction. So the algorithm is basically saying: “I see the motion is causing combing, but behind the hand, I see a man’s chin, neck, and some stubble, so I will fill in the gaps using what I see.”
The algorithms are so good because they have been trained on hundreds of thousands of images and videos from a wide variety of source materials. Most of which feature people, natural scenes, and fully-populated frames. What the algorithms aren’t commonly trained on is bluescreen/chroma key footage.
This results in the following…

Notice how, unlike in the image of Tex with the glass, the algorithms struggle heavily with the edge of Fitzpatrick’s face. This is because they are not as savvy when the edges of subjects where there is no populated data behind where the motion is occurring, making reconstruction very difficult. This means the algorithm (regardless of the deinterlacing method) has no data to reconstruct the edges with, except for plain blue, and its library of data has few examples of this exact scenario to cross-reference.
So, how do we overcome this challenge?
The short answer is: that we are still investigating. Chromakey compositing has gotten very good lately, but it also has its disadvantages. While able to differentiate between the background and a single strand of hair, this also means that this subtle combing will be preserved in the output.

The preservation of the combing when compositing the footage is our biggest challenge. One method would be to “shrink” the matte, which reduces the number of pixels considered the “edge” of the subject. It’s like taking sandpaper and sanding down the rough edges of a sculpture until it is smooth. However, much like in this analogy, if you sand away too much, you end up with a homogenized result that cuts into the details and starts to look strange. However, it is still a possibility if you pick the right field.
As explained above, two full frames are reconstructed from a single frame containing two fields. Here is an example of that output…
Notice how the combing appears to smear outside of the subject’s primary edge in field-A, in contrast to field-B, where the combing encroaches on the subject’s primary edge?
Here are both fields again, this time highlighting the edge of the subject…
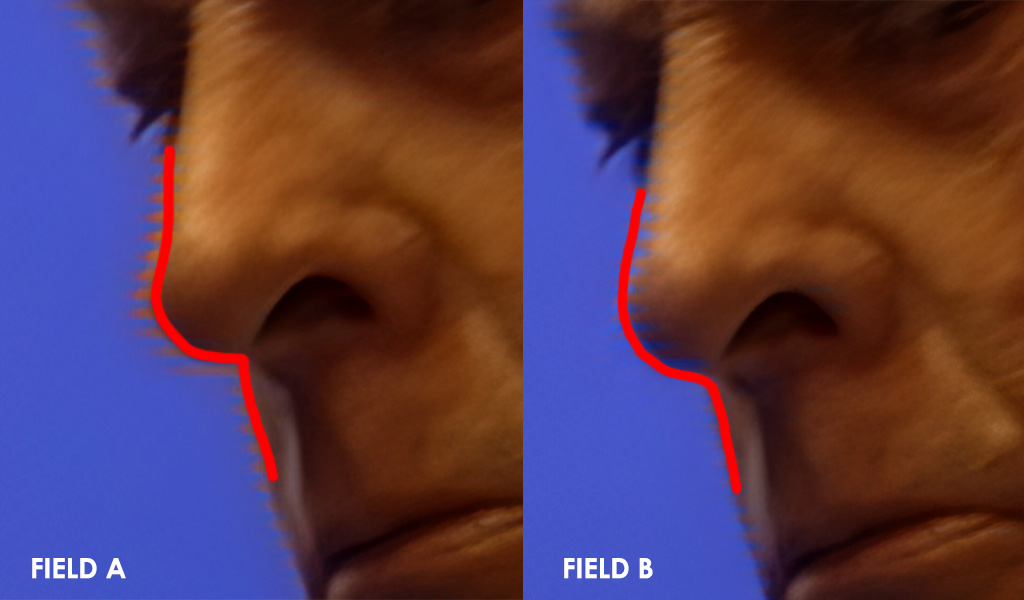
Based on this, we can see that field-A is additive with the field reconstruction data, while field-B is subtractive. So, if we were to use the “shrink” method to “sand away” at the matte to reduce the combing, field-A would retain much more detail than field-B.
But here’s the tradeoff with that method…
In order to pick only the field that takes an additive approach to the combing issue, we would have to discard the second (B) field entirely, thus reducing our framerate from 60 back down to 30. Suffice it to say; we are still currently investigating the best way to overcome this issue without sacrificing our 60fps output.
We’re getting there!
The approach we are taking with this remaster/remake is patience, precision, and passion. We know and understand many of you might be seeing this progress and are eager to play the game, but we are still a small team (albeit, a very dedicated team). We believe The Pandora Directive is Tex’s greatest adventure, and in order to preserve its legacy and even bring it to new gamers, we want to make sure we approach everything the right way. Rest assured, we believe this is the best way to deliver a stellar product that gamers (old and new) will thoroughly enjoy!